2 分钟阅读
基于nodejs做的网页爬虫小项目
已归档 / Archived
这是一篇较早的记录,部分信息可能已经过时,参考意义有限;保留在这里主要作为个人记录。
最近看了慕课网的Nodejs课程,跟着做了一个基于nodejs开发的网页爬虫爬了我自己的博客文章列表,感觉挺有趣的,记录一下。
最终完成的效果如下:
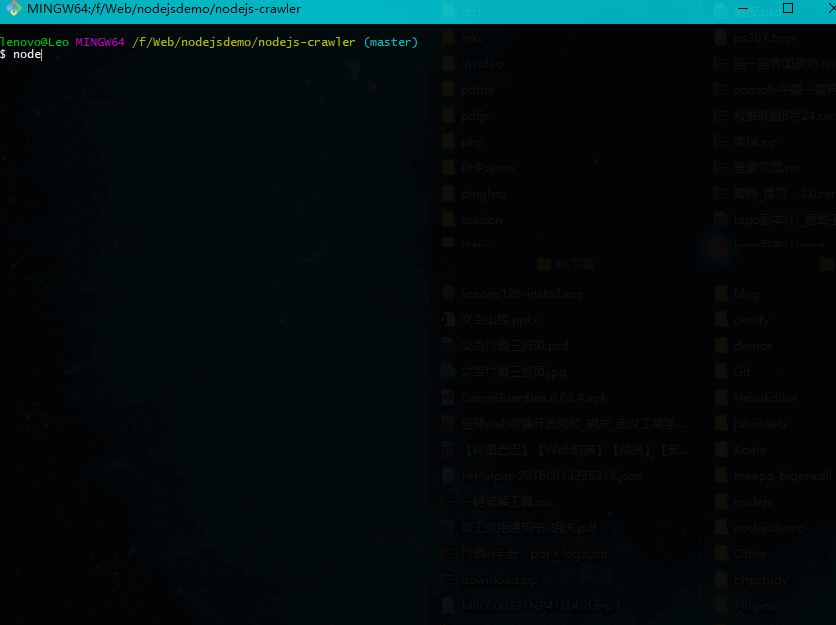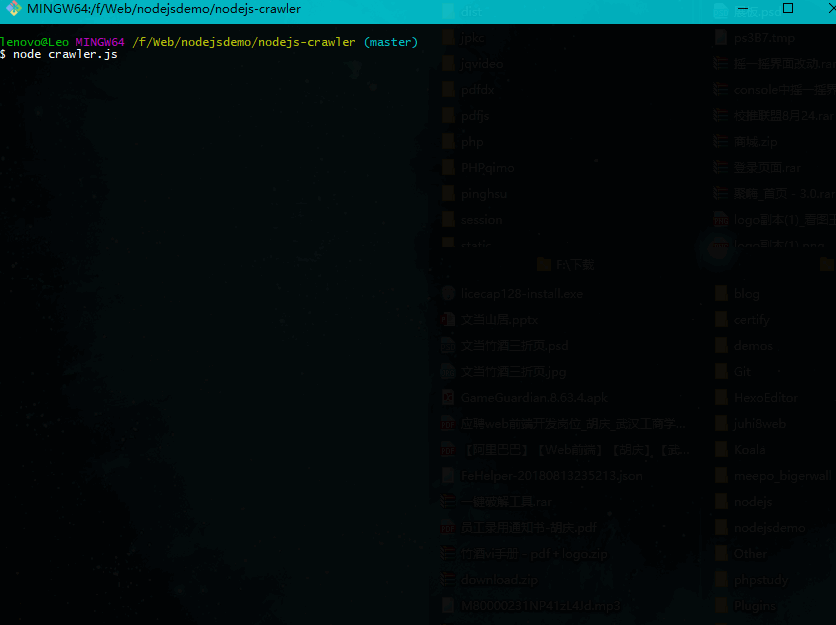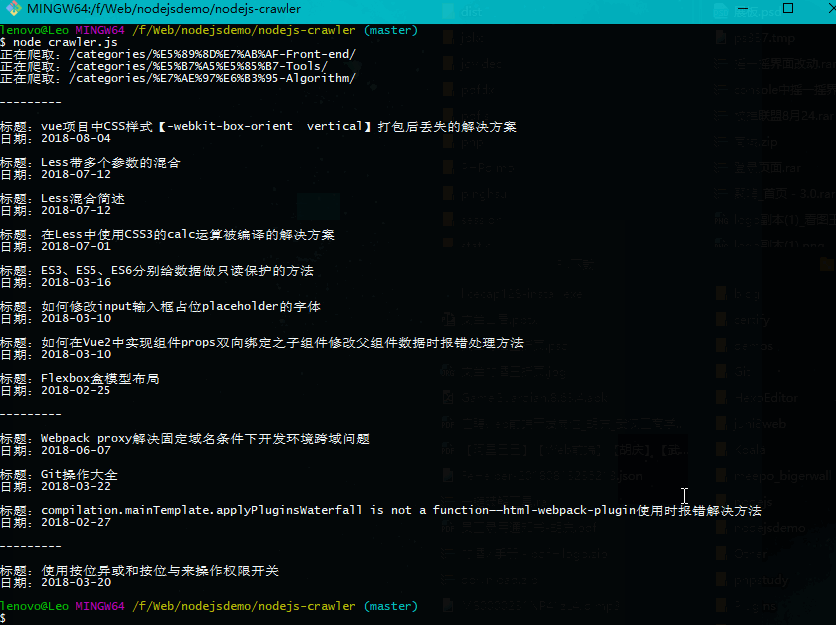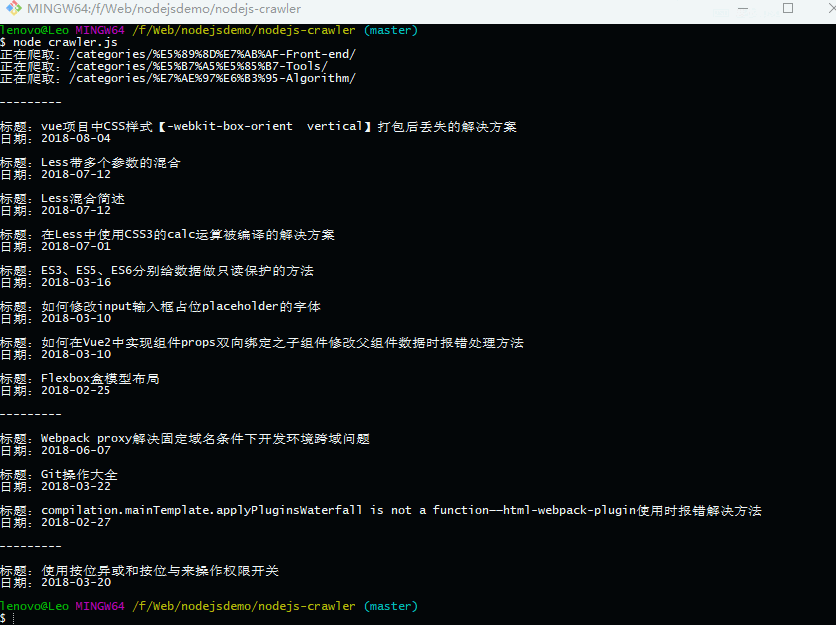
主要步骤
先选择几个目录,根据目录链接,获取每个目录页面的HTML内容
// baseUrl用以拼接url
let baseUrl = '<http://tsing.space>'
// 选择以下三个目录
let categories = [
'/categories/%E5%89%8D%E7%AB%AF-FrontEnd/',
'/categories/%E5%B7%A5%E5%85%B7-Tools/',
'/categories/%E7%AE%97%E6%B3%95-Algorithm/'
]
// 根据url获取HTML内容的方法
function getCatagory(url) {
return new Promise((resolve, reject) => {
console.log('正在爬取:' + url)
http
.get(baseUrl + url, res => {
let data
res.on('data', html => {
data += html
})
res.on('end', () => {
resolve(parseHtml(data))
})
})
.on('error', error => {
console.log('获取数据出错!')
reject(error)
})
})
}
处理HTML获取需要的内容
这里使用到了cheerio这个库,使用方法几乎和jQuery一样
function parseHtml(html) {
const $ = cheerio.load(html)
let articles = $('.post-header')
let parsedData = []
articles.each(function () {
let section = $(this)
let title = section.find('.post-title-link span').text()
let time = section.find('.post-meta time').attr('content')
let item = {
title,
time
}
parsedData.push(item)
})
return parsedData
}
当所有目录都遍历完成后,获取他们的resolve结果,并打印出来
// 输出信息的方法
function printInfo(data) {
console.info('\\n' + '标题:' + data.title + '\\n' + '日期:' + data.time)
}
let articlesData = []
// 将每个promise存入总体状态的数据里
categories.forEach(url => {
articlesData.push(getCatagory(url))
})
// 当所有目录遍历完结再一起处理
Promise.all(articlesData)
.then(res => {
res.forEach(item => {
console.log('\\n---------')
item.forEach(info => {
printInfo(info)
})
})
})
.catch(error => {
console.log(error)
})
总结
如果需要爬取的链接很多,可以先通过cheerio把目录列表中的目录内容获取到,分析其链接并保存
以上就是这个nodejs爬虫小项目的结构了,完整代码可以查看我的Github仓库
评论